[ ELK 란 ]

ELK란 Elastic Search, Logstash, Kibana를 말한다. 이 3가지를 사용하면 로그를 관리하고 검색하기 수월해지며 대시보드를 통해 원하는 정보를 한눈에 확인할 수 있다. Elastic Search는 인덱싱이 되고 있는 DB라고 생각하면 된다. Logstash는 다양한 로그를 Input으로 받아 전처리를 하고 Elastic Search에 쌓을 수 있는 미들웨어라고 보면 된다. Kibana는 Elastic Search에 저장된 데이터를 웹으로 확인할 수 있게 도와주며 대시보드를 통해 데이터에 대한 인사이트를 줄 수 있다.
[ 설치 정보 ]
ELK는 버전 정보가 전부 같다. 그래서 Elastic Search를 7.11.2를 설치한다면 나머지 Logstash와 Kibana도 7.11.2를 설치하면 된다. 어떤 OS에서 설치 가능한지 확인하기 위해서 OS 지원 내역을 검토해봐야 한다. 서버들은 CentOS를 사용하는 경우가 다수 있기 때문에 확인해야 하며 또 어떤 버전의 CentOS를 지원하는지도 확인해야 한다. CentOS 7에 설치할 예정인데 다행히 7.11.2는 전부 해당 버전을 전부 지원하고 있다.
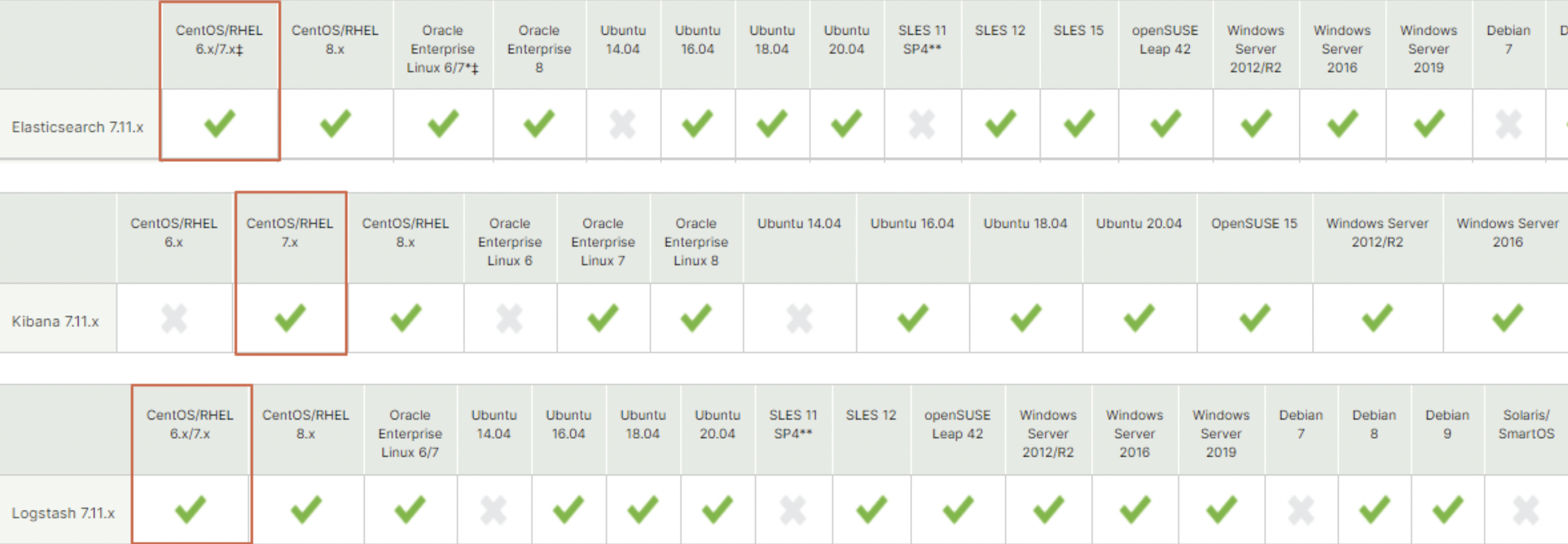
[ 설치 방법 ]
ELK를 설치하기 위해서는 미리 Java 8를 설치해야 한다. OS에 기본적으로 Java 8이 설치되어 있지만 안되어 있을 경우 OpenJDK에서 설치하거나 Oracle에 접속해서 JDK 8을 설치하면 된다. 이게 설치가 되었다면 이제 기본은 끝난 것이다. 설치는 CentOS를 기본으로 한다.
# ubuntu
$ sudo apt-get install openjdk-8-jre
# centos
$ su -c "yum install java-1.8.0-openjdk"
(1) repo 등록
rpm으로 elastic 관련 내용을 import하고 vi로 repo 파일을 만들어서 아래 내용을 그대로 넣어준다.
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
vi /etc/yum.repos.d/elasticsearch.repo이 파일은 Elastic Search, Logstash, Kibana를 설치할 때 1회만 만들어 주면 전부 적용되어 설치가 가능하다.
[elasticsearch]
name=Elasticsearch repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=0
autorefresh=1
type=rpm-md
(2) ELK 설치
yum으로 전부 설치를 진행한다. 버전 정보를 넣어서 모두 같은 버전을 유지할 수 있게 하는 것이 좋다. 마지막에 filebeat는 로그를 실시간으로 logstash에 전달할 수 있는 Agent이므로 설치해서 추가 개발 작업을 없앨 수 있다. Filebeat를 설치하지 않을 경우, 추가로 Agent를 만들어야 하므로 Elastic Search와 같은 생태계에 있는 Filebeat를 사용하는 것을 권장한다.
yum install elastaic-7.11.2
yum install kibana-7.11.2
yum install logstash-7.11.2
yum install filebeat-7.11.2
[ Elastic Search Config ]
vi /etc/elasticsearch/elasticsearch.ymlElastic Search를 설치하면 data는 "/var/lib/elasticsearch", log는 "/var/log/elasticsearch"를 바라보고 있다. 로그는 내버려두어도 되지만 data는 용량이 커질 수 도 있기 때문에 디스크를 추가 마운트해서 "/var/lib/elasticsearch"의 데이터를 새로 마운트한 곳으로 옮겨놓고 사용하면 된다. "/data"에 새로운 디스크를 마운트해서 data 영역으로 사용한다고 하면 "path.data: /data"라고 지정하고 데이터를 전부 복사하고 "chown -R elasticsearch:elasticsearch /data"해서 권한을 변경하면 완료이다.
아래 로그는 총 6대의 서버에 Elastic Search를 설치한 설정이다. 각각의 서버에 path.data부터 discovery.seed_hosts까지의 설정만 넣어주면 된다. node의 이름을 각각 다르게 줘서 설정하고 master로 logstash에서 던지는 로그를 받아주는 서버를 지정한다. 그리고 data만 저장하고 있을 노드를 true, false로 설정하면 완료이다.
host는 기본이 localhost이지만 여러 대의 Elastic Search를 사용한다면 0.0.0.0으로 기입해서 바인딩이 될 수 있게 한다. 그리고 seed_hosts에 Elastic Search를 설치한 IP들을 전부 나열하면 된다.
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
cluster.name: elk-cluster
node.name: "node-1"
node.master: true
node.data: true
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["192.168.100.10", "192.168.100.20", "192.168.100.30", "192.168.100.40", "192.168.100.50", "192.168.100.60"]
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
cluster.name: elk-cluster
node.name: "node-2"
node.master: true
node.data: true
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["192.168.100.10", "192.168.100.20", "192.168.100.30", "192.168.100.40", "192.168.100.50", "192.168.100.60"]
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
cluster.name: elk-cluster
node.name: "node-3"
node.master: true
node.data: true
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["192.168.100.10", "192.168.100.20", "192.168.100.30", "192.168.100.40", "192.168.100.50", "192.168.100.60"]
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
cluster.name: elk-cluster
node.name: "node-4"
node.master: false
node.data: true
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["192.168.100.10", "192.168.100.20", "192.168.100.30", "192.168.100.40", "192.168.100.50", "192.168.100.60"]
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
cluster.name: elk-cluster
node.name: "node-5"
node.master: false
node.data: true
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["192.168.100.10", "192.168.100.20", "192.168.100.30", "192.168.100.40", "192.168.100.50", "192.168.100.60"]
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
cluster.name: elk-cluster
node.name: "node-6"
node.master: false
node.data: true
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["192.168.100.10", "192.168.100.20", "192.168.100.30", "192.168.100.40", "192.168.100.50", "192.168.100.60"]
[ Kibana Config ]
vi /etc/kibana/kibana.yml키바나 설정은 매우 간단한다. 키바나는 6대 서버 중에 한대에만 설치하면 된다. 포트와 호스트 그리고 Elastic Search가 어디에 있는지 정도만 명시하면 끝난다. Elastic Search의 설정에서 node.master가 true인 서버에 키바나를 설치하고 아래와 같이 기입하면 된다. Kibana는 실행 후 "http://192.168.100.10:5601" 와 같이 웹으로 접속하여 확인할 수 있다. 실행 방법은 글 하단에서 확인할 수 있다.
server.port: 5601
server.host: *localhost*
elasticsearch.hosts: ["http://localhost:9200"]
[ Logstash Config ]
vi /etc/logstash/conf.d/first-pipeline.confLogstash는 Filebeat가 던지는 log를 grok을 통해서 각각 분리하고 kv를 통해서 grok으로 분리한 부분을 특정 구분자로 나눈다. 어차피 grok과 kv는 공부해야지 logstash를 제대로 사용할 수 있다. 아래 내용은 logstash에서 filter를 사용하여 if문을 처리하고 output까지 하는 샘플 예제이므로 이런 기능들이 가능하다는 정도라고 알면 좋다.
filter의 patterns_dir은 grok이 사용하는 패턴을 추가할 때 사용할 수 있다. 패턴을 넣은 파일을 만든 후에 원하는 경로에 넣어두고 해당 경로를 patterns_dir에 기입하면 패턴을 사용할 수 있다. 기본 패턴은 여기를 방문하면 알 수 있다.
Logstash는 filter의 if문을 사용해서 여러 filebeat가 던지는 로그를 구분할 수 있다. 구분하는 방법은 [tags]를 활용하는 방법이고 이 방법은 filebeat의 설정을 같이 참조하면서 확인하면 이해라기 편하다. output에서도 if문이 가능하고 filter와 마찬가지로 [tags]를 활용하여 Elastic Search로 삽입한다.
Logstash는 filebeat의 데이터를 처리하다가 전사할 확률이 굉장히 높다. 그렇기 때문에 Elastic Search Config에서 node.master: true로 설정한 서버 3대에 Logstash를 설치하고 아래와 같은 Config를 구성해서 넣는다. 실행할 때 아래 Config를 불러와서 사용하면 3대의 Logstash는 아래 설정으로 동작하게 된다.
#The # character at the beginning of a line indicates a comment. Use
# comments to describe your configuration.
input {
beats {
port => "5044"
host => "0.0.0.0"
}
}
filter{
if "append_log" in [tags] {
grok {
patterns_dir => [ "/usr/share/logstash/bin/patterns" ]
match => [ "message", "\[%{TIMESTAMP_ISO8601:date}\]%{SPACE}%{WORD:server_name}%{SPACE}%{GREEDYDATA:remove_data}%{SPACE}{GREEDYDATA:contents_split}%{SPACE}%{BASE16NUM:guid}" ]
overwrite => [ "message" ]
}
kv {
source => "contents_split"
field_split => "&"
}
mutate {
remove_field => [ "remove_data" ]
}
date {
match => ["log_dt", "yyyyMMdd HH:mm:ss"]
target => "@timestamp"
timezone => "Asia/Seoul"
}
}
}
output {
if "append_log" in [tags] {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "append_log=%{+YYYY.MM.dd}"
}
}
stdout {}
}
[ Filebeat Config ]
vi /etc/filebeat/filebeat.ymlFilebeat는 직접적으로 파일을 모니터링하다가 추가되는 내용을 바로바로 Logstash로 보낸다. 그래서 paths에 원하는 로그를 지정하고 output.logstash에 Logstash가 설치된 서버의 IP와 Port를 넣고 기타 설정 내용도 빠짐없이 넣어주면 문제없이 동작한다.
Logstash의 filter에서 if문으로 활용한 [tags]는 Filebeat의 config에서 "tags: ["append_log"] 에서 확인할 수 있다. 이렇게 tags를 활용하면 여러 로그들을 구분해서 Logstash에 보낼 수 있어서 매우 편리하다. 정식 문서에서는 이 부분이 명확하게 나와 있지 않아 if문을 구현하기 힘들었는데 많은 검색와 테스트로 알아낸 방법이다.
filebeat.inputs:
- type: log
enabled: true
paths:
- /logs/system.log*
tags: ["append_log"]
- type: filestream
enabled: false
paths:
- /var/log/*.log
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 1
setup.kibana:
output.logstash:
hosts: ["192.168.100.10:5044","192.168.100.20:5044","192.168.100.30:5044"]
processors:
- add_host_metadata:
when.not.contains.tags: forwarded
- add_cloud_metadata: ~
- add_docker_metadata: ~
- add_kubernetes_metadata: ~
[ ELK 서비스 시작과 종료 그리고 재시작 ]
기본적으로 systemctl을 통해서 elasticsearch, logstash, kibana, filebeat를 실행할 수 있다.
systemctl start elasticsearch
systemctl start logstash
systemctl start kibana
systemctl start filebeat
systemctl restart elasticsearch
systemctl restart logstash
systemctl restart kibana
systemctl restart filebeat
systemctl stop elasticsearch.service
systemctl stop logstash.service
systemctl stop kibana.service
systemctl stop filebeat.service
하지만 logstash와 filebeat는 특정 설정 파일을 불러와서 실행해야 하므로 아래와 같이 실행하면 된다.
sudo /usr/share/logstash/bin/logstash -f /usr/share/logstash/bin/first-pipeline.conf
/usr/share/filebeat/bin/filebeat -e -c /etc/filebeat/filebeat.yml
위와 같이 동작시키면 서비스가 전사했을 때에는 스스로 재구동되지 않는다. 그래서 스스로 재구동하게 하기 위해서는 systemctl을 조금 손봐줘야 하는데 systemctl을 설정하는 방법은 다음 글에서 안내하도록 하겠다.
'동굴 속 정보' 카테고리의 다른 글
| 개발자라면 주식 백테스팅은 해보자 (0) | 2021.05.23 |
|---|---|
| 리눅스 ELK 서비스 등록 (0) | 2021.05.09 |
| Binary Tree Traversal, DFS, BFS (0) | 2021.04.25 |
| Hash Table과 Collision (0) | 2021.04.24 |
| 점화식 Recusion Tree로 풀기 (0) | 2021.04.21 |



