[ 카프카의 이해 ]
카프카(Kafka)는 스트리밍 데이터를 위한 미들웨어이다. 고가용성(Highly Available)과 고확장성(Highly Scalable)한대 데이터 영속성(Data Persistence)까지 갖추었다. 고가용성이란 오랜 기간 동안 지속적으로 정상 운영이 된다는 의미이고 고확장성은 병렬 시스템이 가능하다는 의미이다. 그리고 영속성은 프로그램이 종료돼도 사라지지 않는 데이터를 말한다.
카프카는 "Producer" > "Broker Cluster" > "Consumer" 라는 3가지 컴포넌트를 가지고 있다. Pub/Sub 구조로 움직이며 Topic 이라고 불리는 데이터 관리 유닛을 사용한다. 이러한 구조의 작업들이 Zookeeper에 의해 관리된다. Producer는 데이터를 입력하는 클라이언트이다. Broker Cluster는 데이터를 호스팅해주고 Consumer는 데이터를 가져오는 클라이언트이다. 하나의 Topic에 여러 Consumer가 붙어서 목적에 맞게 데이터를 가져간다.
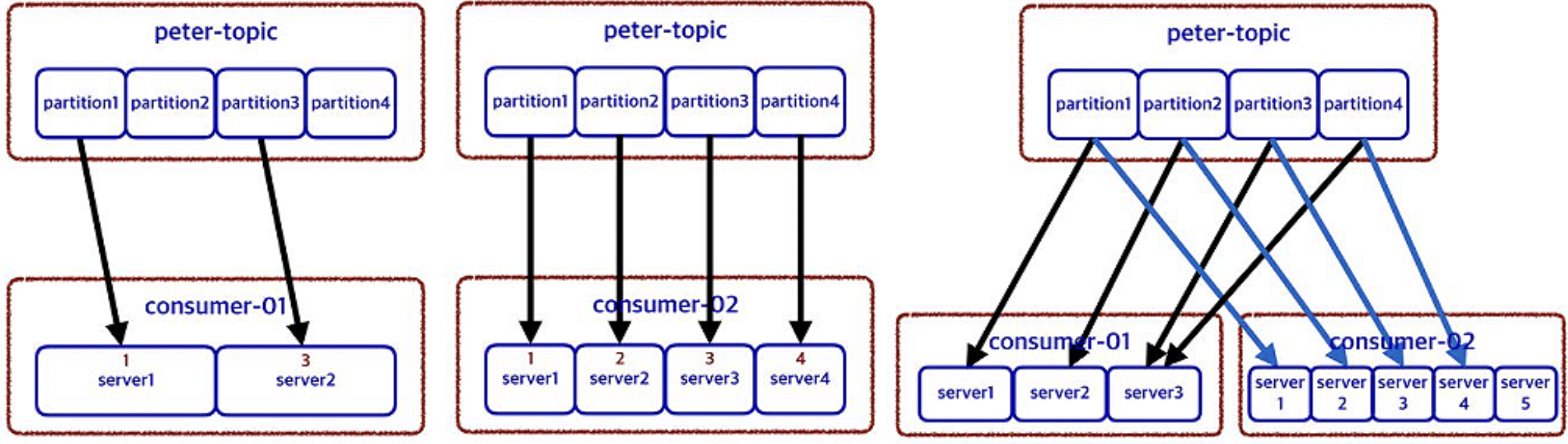
Consumer는 그룹으로 운영이 가능하다. 각 그룹 내의 서버들끼리는 서로의 정보를 공유하고 있으며 그룹 내 서버 중 일부가 정지하여도 다른 서버가 업무를 대신한다. 또한 Consumer 그룹은 해당 그룹에 대한 offset을 관리한다. offset을 사용하여 데이터를 전송한 내용을 기억한다.
- 예1 > consumer-01['server1', 'server2', 'server3']
- 예1 > consumer-01['server1', 'server2', 'server3']

Topic에는 Partition이 여러개 존재하는데 server1이 특정 Partition1에 접근할 때 다른 server들은 해당 Partition에 접근하지 못한다. 대기가 많아지면 효율이 나오지 않기 때문에 Partition의 개수와 Server의 개수를 동일하게 맞추는 게 좋고 적어도 절반 정도 수준으로 구성하는 것이 좋다.
예를 들어, 하나의 Consumer 그룹에 server1, server2, server3 이라는 3개의 인스턴스가 존재하다면 Partition도 3개의 Partition인 Partition1, Partition2, Partition3으로 맞춰 주는 것이 좋다.
[ kafka 설치 ]
kafka의 설치는 매우 간단하다. 위 내용을 이해하고 있으면 설치하고 사용하는데 큰 문제는 없다. 가장 중요한 건 용어에 익숙해 지는 것이다. 용어에 익숙해지면 어떻게 사용해야 하는지를 빠르게 이해할 수 있다. 단계는 총 7단계가 있으며 카프카(Kafka) 다운로드부터 실행까지 순서대로 진행된다.
- JDK 8을 설치한다.(링크)
- Kafka를 다운로드 한다.(링크)
- 다운로드한 Kafka의 압축을 푼다.
- Kafka 설정 파일을 수정한다. (./config/server.properties)
port = 9092 advertised.host.name = localhost delete.topic.enable = true- 설정 파일 안의 LOG Directory를 업데이트한다. (./config/server.properties)
log.dir = c:\kafka_2.12-2.4.0 - ZooKeeper 실행 (c:\kafka_2.12-2.4.0\bin\windows\), Port 2181
zookeeper-server-start.bat ../../config/zookeeper.properties - Kafka 실행 (c:\kafka_2.12-2.4.0\bin\windows\), Port 9092
kafka-server-start.bat ../../config/server.properties
[ kafka-python 설치와 사용법 ]
kafka-python은 kafka가 실행된 이후에 사용할 수 있는 Python 도구이다. 자바나 스칼라 언어로 사용이 되는 Kafka 지만, Python으로도 사용할 수 있는 도구를 제공하다 보니 매우 편리하지 않을 수 없다. 간단한 설치와 Producer구현과 Consumer 구현에 대해서 알아보겠다.
- 설치
먼저 설치를 진행한다. (파이썬이 설치된 상태여야 한다.)
pip install kafka-python
- Producer 구현
Producer를 구현한다. 코드를 보면 KafkaProcucer를 여러 옵션을 사용해서 생성하고 for문으로 한 줄 한 줄 입력하는 것을 볼 수 있다. 이때 send()라는 함수를 사용하고 입력이 되면 flush()로 다시 비워주는 행위를 반복하면서 입력을 넣어준다. KafkaProducer에서 사용하는 옵션은 하단에서 확인할 수 있다.
from kafka import KafkaProducer
from json import dumps
import time
import numpy as np
#Producer 객체를 생성한다.
producer = KafkaProducer(
bootstrap_servers=['localhost:9092'],
acks=0,
compression_type='gzip',
value_serializer=lambda x: dumps(x).encode('utf-8')
)
start = time.time()
range_num = 1000
rand_nums = np.random.rand(range_num)
for i in range(range_num):
data = {str(i) : 'result'+str(rand_nums[i])}
producer.send('test', value=data)
producer.flush()
print("elapsed :", time.time() - start)
Kafka 9092 서버에서 로그를 확인할 수 있다. (c:\kafka_2.12-2.4.0\bin\windows\)
kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test
- consumer 구현
consumer 구현을 위해 KafkaConsumer 객체를 생성한다. Producer와 마찬가지로 여러 옵션을 사용해서 생성하는데 옵션은 코드 하단에서 확인할 수 있다.
from kafka import KafkaConsumer
from json import loads
# Consumer 객체를 만든다.
consumer = KafkaConsumer(
'test',
bootstrap_servers=['localhost:9092'],
auto_offset_reset='latest',
enable_auto_commit=True,
group_id='group-1',
consumer_timeout_ms=1000,
value_deserializer=lambda x: loads(x.decode('utf-8')),
)
# consumer list를 가져온다
print('[start] get consumer list')
for message in consumer:
print(
"Topic: %s, Partition: %d, Offset: %d, Key: %s,
Value: %s" % ( message.topic, message.partition,
message.offset, message.key, message.value )
)
print('[end] get consumer list')
'동굴 속 정보' 카테고리의 다른 글
| 그림 그릴꺼 아니면 그냥 아이패드 미니 사라 (0) | 2022.04.18 |
|---|---|
| 애드센스 수익 통장으로 받기 (0) | 2022.04.09 |
| 지금도 쓸만한 아이패드 미니 3세대 (0) | 2021.08.02 |
| numpy.core._exceptions.MemoryError (2) | 2021.08.01 |
| M1 맥으로 윈도우용 개발 환경 구축 (0) | 2021.05.24 |



